IntelliDecision.ai
User Manual
IntelliDecision.ai User Manual
IntelliDecision.ai is a no-code, enterprise-grade decision intelligence platform designed to help organisations build, evaluate, deploy, and govern predictive models and decision strategies at scale.

Built by Corestrat, IntelliDecision.ai eliminates the traditional complexity of machine learning and statistical modelling by embedding advanced AI, automated feature engineering, model optimisation, and decision logic into a guided, intuitive workflow. The platform enables both data scientists and business users to collaborate on building explainable, auditable, and production-ready decision systems, without writing a single line of code.
2. Who IntelliDecision.ai Is For
IntelliDecision.ai is purpose-built for:
- Financial Services & Fintech (credit risk, underwriting, fraud, collections)
- Insurance (risk selection, pricing, claims triage)
- Retail & E‑commerce (customer scoring, churn, offer optimisation)
- Logistics & Supply Chain (delay risk, vendor risk, demand forecasting)
- Enterprises adopting AI-driven decision automation

Key user personas include: - Risk & Analytics Teams - Business Analysts - Data Scientists - Product Managers - Compliance & Model Governance Teams - Technology & Platform Teams
3. Key Capabilities
No-code / low-code model development
End-to-end ML lifecycle management
Advanced data preprocessing & feature engineering
Automated and manual model building
Explainability via IV, WoE, SHAP, KS, Gini
API-based deployment
Auto documentation & audit readiness
Enterprise-Grade Platform
Built for scale with comprehensive governance and compliance features
4. Platform Architecture & Workflow
IntelliDecision.ai follows a structured six-stage decision intelligence pipeline:
Data Ingestion & Project Setup
Data Preparation & Feature Engineering
Sampling & Target Definition
Model Development & Comparison
Model Evaluation & Explainability
Decision Design, Simulation & Deployment
Each stage is fully integrated, traceable, and configurable.
5. Data Ingestion & Project Management
Project Creation
- Create new projects or refine existing ones
- Maintain multiple versions and assumptions
- Import projects from different environments


Data Upload Options
- File-based upload: CSV, Excel, Feather, Parquet, delimited text
- Database ingestion: Databricks, MySQL, Snowflake
- SQL-based data extraction
Advanced Dataflow Builder (ADB)
The Advanced Dataflow Builder enables complex data preparation using a visual, drag-and-drop canvas:
This allows enterprise-grade data engineering—without external ETL tools.
6. Data Preprocessing & Management
Users can choose between: - Let AI Do It (fully automated preprocessing) - Do It Yourself (manual control)
Core Preprocessing Features
Variable Treatment & Governance
- Identify sensitive variables (e.g. age, gender)
- Flag high-missing or low-information variables
- Support fairness-aware modelling
Missing Value Handling
- Imputation (mean, median, mode)
- Missingness indicators
- Smart AI-driven replacement
Outlier Detection
- Percentile-based capping
- IQR-based trimming
- Custom thresholds
Normalisation & Scaling
- Min-max scaling
- Z-score standardisation
- Robust scaling for outliers
Preprocessing can be fully automated via AI or customised step-by-step for full transparency and control.
7. Feature Engineering & Transformation
Feature Engineering Options
- Code‑It‑Yourself Python feature creation
- Variable picker for rapid coding
- Two-way interaction creation
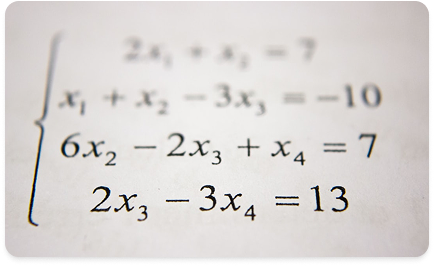
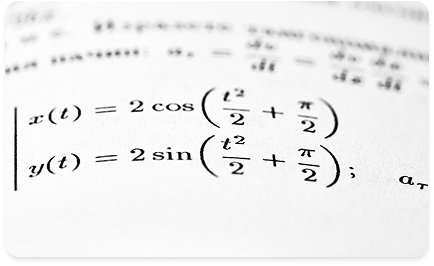
Variable Transformation
- Automated (AI-selected best transformations)
- Manual (individual or batch)
- Retain original and/or transformed variables
Category Encoding
- One-Hot Encoding
- Frequency Encoding
- Batch or variable-level control
Distribution Analysis
- Interactive histograms for numerical variables
- Adjustable binning
- Categorical frequency visualisations
- Outlier and percentile insights
Feature engineering tools allow users to create, transform, and encode variables — either manually or with AI assistance — ensuring models are built on the most predictive inputs.
8. Sampling & Target Definition
Target Variable Selection
- Auto-identification of candidate target variables
- Define positive vs negative outcome categories

Stratified Sampling
- Default 70/30 train-test split
- Customisable ratios
- Ensures target distribution stability
Proper sampling and target definition are critical for building accurate, unbiased predictive models.
9. Variable Insights, Binning & Selection
Information Value (IV) Analysis
- Fine & final classing
- Correlation assessment
- Inferred relationship detection
- Manual & IV-optimal binning (numeric & categorical)
Clustering (VarClus)
- Cluster variables using WoE or original values
- Variance retention or cluster count control
- Automatic representative variable selection
Multicollinearity Management
- Correlation matrix
- VIF-based variable classification
- Automated correlated variable pruning
Variable Lineage View
- Full trace of variables added, removed, transformed
- End-to-end transparency

10. Model Development & AutoML
Supported Model Types
Decision Trees
Logistic Regression
Random Forest
XGBoost
Neural Networks

Model Settings
- Global parameters (node size, depth, IV, VIF)
- Score scaling (Base Score, PDO, Odds)
- Algorithm-specific hyperparameters
Auto Grow Trees
- Automated tree growth
- Manual split insertion
- Node collapse & override
- IV-guided split recommendations
AutoML (Model.ai)
- One-click model training
- Bayesian hyperparameter optimisation
- Model-specific explainability
11. Model Comparison & Ensembling
Build up to 3 models
Compare using KS, Gini, AUC, F1
Traffic-light performance indicators
Model ensembling (averaging / weighted)
Final model selection

Compare multiple models side-by-side and create powerful ensembles for optimal performance.
12. Model Evaluation & Explainability
Performance Metrics
- KS & Gini (Train vs Test)
- ROC & AUC
- Confusion matrix
- Precision, Recall, F1-Score
Explainability Tools
- SHAP values
- Variable importance rankings
- Decision path visualisation
- Business-friendly reports

13. Decision Design, Simulation & Deployment
Decision Strategy Builder
- Rule-based decision logic
- Score-to-action mapping
- Multi-stage approval workflows
- Champion-challenger testing

Deployment Options
- REST API endpoints
- Batch scoring
- Real-time scoring
- Version control and rollback
Design, simulate, and deploy decision strategies with full control and monitoring capabilities.
14. Auto Documentation & Governance
Automated Documentation
- Complete model development audit trail
- Data lineage tracking
- Model cards and metadata
- Regulatory-ready reports
Governance & Compliance
- Role-based access control
- Approval workflows
- Model risk management
- Compliance with SR 11-7, BASEL, IFRS 9

Enterprise-Ready Platform
IntelliDecision.ai provides comprehensive governance, documentation, and compliance features to meet the strictest enterprise and regulatory requirements.